


The Marvels and the Flaws of Intuitive Thinking - Daniel Kahneman, Nobel Prize Winner, Princeton
The power of settings, the power of priming, and the power of unconscious thinking, all of those are a major change in psychology. I can't think of a bigger change in my lifetime. You were asking what's exciting? That's exciting, to me.

DANIEL KAHNEMAN is the Eugene Higgins Professor of Psychology Emeritus, Princeton University; Recipient, the 2002 Nobel Prize in Economic Sciences; Author, Thinking Fast and Slow (forthcoming, October 25, 2011).
Daniel Kahneman's Edge Bio Page
In July, Edge held its annual Master Class in Napa, California on the theme: "The Science of Human Nature". In the coming weeks we will publish the complete video, audio, and texts: Princeton psychologist Daniel Kahneman on the marvels and the flaws of intuitive thinking; Harvard mathematical biologist Martin Nowak on the evolution of cooperation; UC-Santa Barbara evolutionary psychologist Leda Cosmides on the architecture of motivation; UC-Santa Barbara neuroscientist Michael Gazzaniga on neuroscience and the law; Harvard psychologist Steven Pinker on the history of violence; and Princeton religious historian Elaine Pagels on The Book of Revelations. For publication schedule and details, go to Edge Master Class 2011: The Science of Human Nature.
Transcript
DANIEL KAHNEMAN: The marvels and the flaws that I'll be talking about are the marvels and the flaws of intuitive thinking. It's a topic I've been thinking about for a long time, a little over 40 years. I wanted to show you a picture of my collaborator in this early work. What I'll be trying to do today is to sort of bring this up-to-date. I'll tell you a bit about the beginnings, and I'll tell you a bit about how I think about it today.
 |
 |
This is Amos Tversky, with whom I did the early work on judgment and decision-making. I show this picture in part because I like it, in part because I like very much the next one. That's what Amos Tversky looked like when the work was being done. I have always thought that this pairing of the very distinguished person, and the person who is doing the work tells you something about when good science is being done, and about who is doing good science. It's people like that who are having a lot of fun, who are doing good science.
We focused on flaws of intuition and of intuitive thinking, and I can tell you how it began. It began with a conversation about whether people are good intuitive statisticians or not. There was a claim at the University of Michigan by some people with whom Amos had studied, that people are good intuitive statisticians. I was teaching statistics at the time, and I was convinced that this was completely false. Not only because my students were not good intuitive statisticians, but because I knew I wasn't. My intuitions about things were quite poor, in fact, and this has remained one of the mysteries, and it's one of the things that I'd like to talk about today — what are the difficulties of statistical thinking, and why is it so difficult.
We ended up studying something that we call "heuristics and biases". Those were shortcuts, and each shortcut was identified by the biases with which it came. The biases had two functions in that story. They were interesting in themselves, but they were also the primary evidence for the existence of the heuristics. If you want to characterize how something is done, then one of the most powerful ways of characterizing the way the mind does anything is by looking at the errors that the mind produces while it's doing it because the errors tell you what it is doing. Correct performance tells you much less about the procedure than the errors do.
We focused on errors. We became completely identified with the idea that people are generally wrong. We became like prophets of irrationality. We demonstrated that people are not rational. We never liked this, and one of the reasons we didn't was because we were own our own best subjects. We never thought we were stupid, but we never did anything that didn't work on us. It's not that we're studying the errors of other people, we were constantly studying the way our own minds worked, and even when we knew better, we were able to tell what were the mistakes that were tempting to us, and basically we tried to characterize what were the tempting mistakes.
That was 40 years ago, and a fair amount has happened in the last 40 years. Not so much, I would say, about the work that we did in terms of the findings that we had. Those pretty much have stood, but it's the interpretation of them that has changed quite a bit. It is now easier than it was to speak about the mechanisms that we had very little idea about, and to speak about, to put in balance the flaws that we were talking about with the marvels of intuition. We spent most of our time on flaws because this is was what we were doing. We did not intend the message that was in fact conveyed that the flaws are what this is about. In fact, this is something that happens quite a lot, at least in psychology, and I suppose it may happen in other sciences as well. You get an impression of the relative importance of two topics by how much time is spent on them when you're teaching them. But you're teaching what's happening now, you're teaching what's recent, what's current, what's considered interesting, and so there is a lot more to say about flaws than about marvels.
Most of the time everything we do is just fine, but how long can you spend saying that most of what we do is just fine? So we focused a lot on what is not fine, but then the students and the field get the impression that you're only interested in what is not fine. That is something that happened to us fairly early. We didn't do enough to combat it. But there was very little we could do to combat it because most of our work was about flaws. In recent years it is becoming more even. We understand the flaws and the marvels a little better than we did.
 |
 |
One of the things that was was not entirely clear to us when we started, and that has become a lot clearer now, was that there are two ways that thoughts come to mind. One way a thought can come to mind involves orderly computation, and doing things in stages, and remembering rules, and applying rules. Then there is another way that thoughts come to mind. You see this lady, and she's angry, and you know that she's angry as quickly as you know that her hair is dark. There is no sharp line between intuition and perception. You perceive her as angry. Perception is predictive. You know what she's going to say, or at least you know something about what it's going to sound like, and so perception and intuition are very closely linked. In my mind, there never was a very clean separation between perception and intuition. Because of the social context we're in here, you can't ignore evolution in anything that you do or say. But for us, certainly for me, the main thing in the evolutionary story about intuition, is whether intuition grew out of perception, whether it grew out of the predictive aspects of perception.
If you want to understand intuition, it is very useful to understand perception, because so many of the rules that apply to perception apply as well to intuitive thinking. Intuitive thinking is quite different from perception. Intuitive thinking has language. Intuitive thinking has a lot of world knowledge organized in different ways than mere perception. But some very basic characteristics that we'll talk about of perception are extended almost directly into intuitive thinking.
What we understand today much better than what we did then is that there are, crudely speaking, two families of mental operations, and I'll call them "Type 1" and "Type 2" for the time being because this is the cleaner language. Then I'll adopt a language that is less clean, and much more useful.
Type 1 is automatic, effortless, often unconscious, and associatively coherent, and I'll talk about that. And Type 2 is controlled, effortful, usually conscious, tends to be logically coherent, rule-governed. Perception and intuition are Type 1— it's a rough and crude characterization. Practiced skill is Type 1, that's essential, the thing that we know how to do like driving, or speaking, or understanding language and so on, they're Type 1. That makes them automatic and largely effortless, and essentially impossible to control.
Type 2 is more controlled, slower, is more deliberate, and as Mike Gazzaniga was saying yesterday, Type 2 is who we think we are. I would say that, if one made a film on this, Type 2 would be a secondary character who thinks that he is the hero because that's who we think we are, but in fact, it's Type 1 that does most of the work, and it's most of the work that is completely hidden from us.
I wouldn't say it's generally accepted. Not everybody accepts it, but many people in cognitive and in social psychology accept that general classification of families of mental operations as quite basic and fundamental. In the last 15 years there has been huge progress in our understanding of what is going on, especially in our understanding of Type 1 thought processes. I'd like to start with this example, because it's nice.
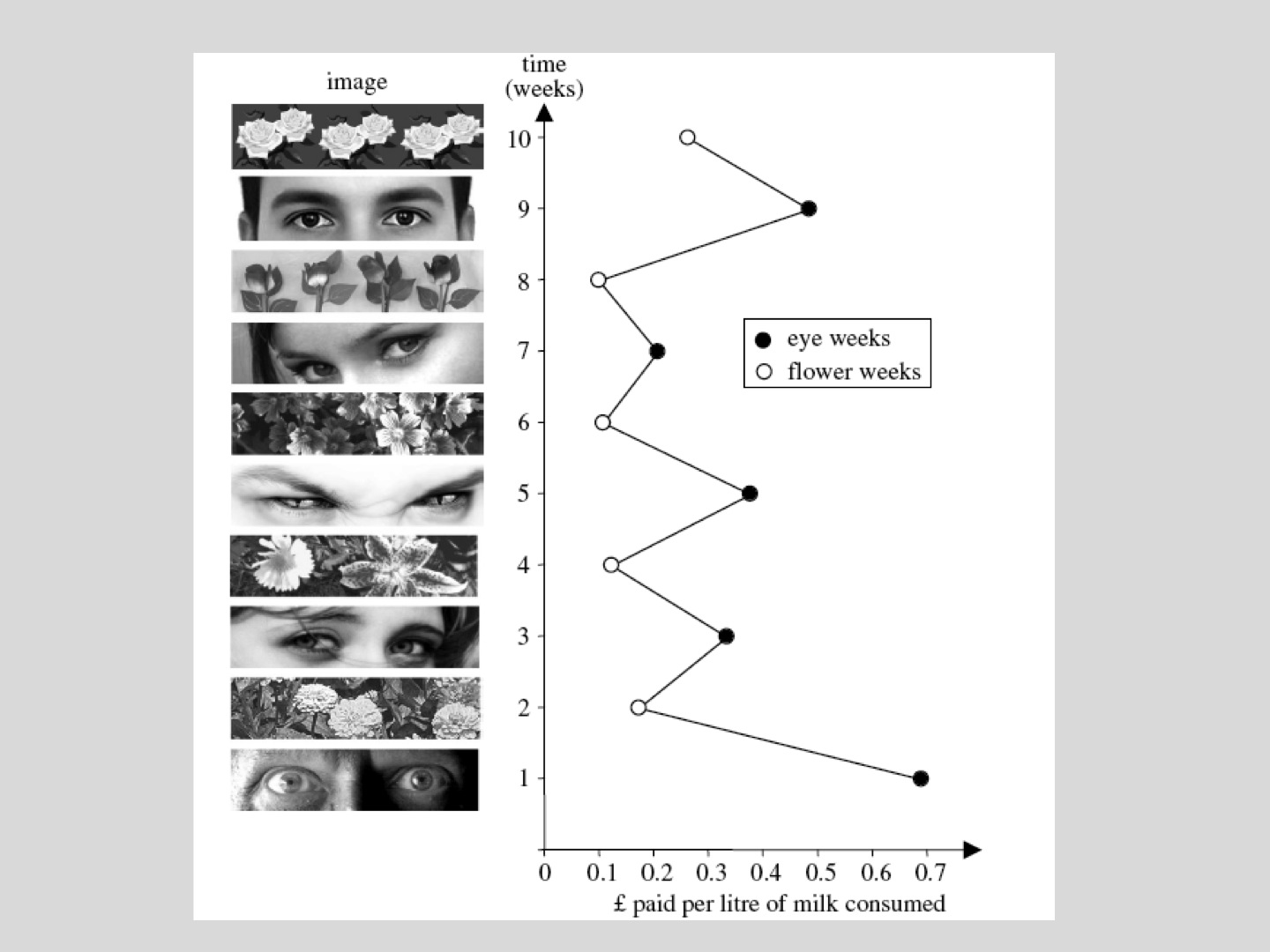
This is a report of the study that was carried out in a kitchen at some university in the UK, and that kitchen has an honesty system where people put in money when they buy tea and milk, and this is per liter of milk consumed, and somebody had the bright idea of putting a poster right on top of where the milk and the tea are, and of changing the poster every week. You can see that the posters alternate week by week, they alternate flowers and eyes, and then you can see how much people are paying. It starts from the bottom, which is the biggest effect, and this thing speaks for itself. It shows the enormous amount of control that there is, a thing that people are completely unaware of. Nobody knew that the posters had anything to do with anything. The posters are eyes, the eyes are symbols, somebody is watching, and that has an effect and you contribute more.
The power of settings, and the power of priming, and the power of unconscious thinking, all of those, are a major change in psychology. I can't think of a bigger change in my lifetime. You were asking what's exciting? That's exciting, to me.
This is an extreme case of Type 1. It's completely unconscious and very powerful, mixes cognition and motivation in a way that is inextricable and has a lot of control over behavior.

Let me propose what's happened in your minds over the last few seconds as you were looking at this display of two words. Everything that I'm going to say is very well-defended in recent research, mostly in research over the last 10, 15 years. You saw those two words. People recoil from the word "vomit". You actually move backward, and that has been measured. You make a face of disgust. It's not very obvious, but there is a disgust face being made. You feel a bit bad. The disgust face makes you feel worse because we know that forcing, shaping people's face into a particular expression changes the way they think and the way they feel. All of this happened. You are now prepared. Then something else happens. You have those two words that have nothing to do with each other, you made a story. There is now a connection between those two, the banana has somehow caused the vomit, and temporarily you're off bananas. They're sort of past. This is not something you want.
Quite interesting. What happens is that your associative structure, your associative memory (and I'm going to be speaking mostly of what happens in associative memory), has changed shape. You have to think of it as a huge repository of ideas, linked to each other in many ways, including causal links and other links, and activation spreading from ideas to other ideas until a small subset of that enormous network is illuminated, and that subset is what's happening in the mind at the moment. You're not conscious of it, you're conscious of very little of it, but this is what happens. Among the links that are activated, anything to do with vomit is going to be activated. All the words, "sickness", "hangover", you name it, and the fact that they're activated means that you're prepared for them.
This is a very interesting function, this whole arrangement. You have a mini-reaction to what is happening, that is sort of a faint replica of reacting to the real event, and it prepares you for things that will go next. Being prepared means that you will need less stimulation in order to recognize a word, so that's the main thing. The amount of energy that it takes for a word to register is going to be sharply reduced for all the words that have to do with "vomit", and many of the words that have to do with "banana".
Links are going to be created, and in particular, and that's a fascinating part of it. You made up a causal story, that is the vomit, which looks like an effect here, is looking for causes, and so you are making up scenarios. All of this is happening involuntarily, most of it is happening unconsciously, but you are primed, and you are ready for what comes next, after that particular stories of bananas causing vomit.
One other thing that I find most striking about this whole story that we've learned in the past 10, 15 years is what I call "associative coherence." Everything reinforces everything else, and that is something that we know. You make people recoil; they turn negative. You make people shake their heads (you put earphones on people's heads, and you tell them we're testing those earphones for integrity, so we would like you to move your head while listening to a message, and you have them move their head this way, or move their head that way, and you give them a political message) they believe it if they're doing "this", and they don't believe it if they're doing "that". Those are not huge effects, but they are effects. They are easily shown with a conventional number of subjects. It's highly reliable.
The thing about the system is that it settles into a stable representation of reality, and that is just a marvelous accomplishment. That's a marvel. This is not. That's not a flaw, that's a marvel. Now, coherence has its cost. Coherence means that you're going to adopt one interpretation in general. Ambiguity tends to be suppressed. This is part of the mechanism that you have here that ideas activate other ideas and the more coherent they are, the more likely they are to activate to each other. Other things that don't fit fall by the wayside. We're enforcing coherent interpretation. We see the world as much more coherent than it is.
That is something that we see in perception, as well. You show people ambiguous stimuli. They're not aware of the ambiguity. I'll give you an example. You hear the word "bank", and most people interpret "bank", as a place with vaults, and money, and so on. But in the context, if you're reading about streams and fishing, "bank" means something else. You're not conscious when you're getting one that you are not getting the other. If you are, you're not conscious ever, but it's possible that both meanings are activated, but that one gets quickly suppressed. That mechanism of creating coherent interpretations is something that happens, and subjectively what happens (I keep using the word "happens" - this is not something we do, this is something that happens to us). The same is true for perception. For Plato it was ideas sort of thrusting themselves into our eyes, and that's the way we feel. We are passive when it comes to System 1. When it comes to System 2, and to deliberate thoughts, we are the authors of our own actions, and so the phenomenology of it is radically different.
I wanted to give you a sense of the way I think about intuitive thinking these days, and from that point, I make a move that many people are going to be very angry with me about. Instead of talking about Type 1 and Type 2 processes I adopt terminology - It's not mine, but the people who proposed it have now repudiated, and have moved to Type 1 and Type 2 - I use System 1 and System 2. System 1 does all sorts of things, and System 2 does other things, and I describe what is going on in our mind as a psychodrama between two fictitious characters.
System 1 is one character, and System 2 is another character, and they battle it out. They each have their own preferences, and their own ways of doing things. I will apologize ahead of time for why I'm doing this, because I don't believe that there are systems in the brain, systems in the sense of interacting parts and so on. But it turns out that our memory and our minds are shaped in such a way that certain operations are a lot easier for us than others.
A book that I read recently that I recommend is Moonwalking with Einstein. In that book Joshua Foer described how in one year he turned himself into the memory champion of the United States using techniques that have been around since the Greeks. The point that he makes is quite straightforward. We are very, very bad at remembering lists. We are very, very good at remembering routes. We can remember routes; we don't remember lists. If you arrange a list along your route, you're going to remember the list, and that's basically the idea.
It turns out there is something else we're awfully good at. We're good at taking an agent and assigning characteristics to that agent, and remembering that this agent has these certain habits, and it does these things. If you want to learn about System 1 and System 2, or about Type 1 and Type 2 operations, really the same, think of it as System 1 and 2. it will develop a personality. There are certain things that it likes doing, that it's able to do, and there are certain things it just cannot do, and you will get that image. It's completely crazy. There is no such thing as these two characters but at the same time, I find it enormously useful. And it's quite funny, I'm losing friends over this. People will tell me, you're bringing psychology backward 50 years, because the idea of having little people in the mind is supposed to be a grave sin. I accept it's a grave sin. But it really helps you when you think of those characters in the mind with their own characteristics. So I'll give you a few examples.
What can System 1 do? I'll give you one example of the translation. What operations are conducted, automatically and without thinking, Here is one. We can detect incongruity and abnormality automatically, without thinking, and very, very quickly. And the subtly of it is amazing. To give you an example, my favorite. You have an upper class British voice, a male British voice saying, "I have tattoos, I have large tattoos all down my back." Two hundred and fifty milliseconds the brain has a response: something is wrong. People who speak in upper class British voices don't have large tattoos down their back. A male voice saying, "I believe I'm pregnant", 200 milliseconds later, males don't become pregnant. This is something that happens. The world knowledge that is brought to bear is enormous — the amount of information that you would have to know and to be able to bring to bear instantly in order to know there's something incongruous here — and that happens at a speed that is extraordinary. This is just about as fast as you can pick up anything in the brain, between 200 and 400 milliseconds there is a full-blown surprise response. That's one of the things that System 1 does.
System 1 infers and invents causes and intentions. And that, again, is something that happens automatically. Infants have it. We were exposed to that. Infants can recognize intention, and have a system that enables them to divine the intentions of objects that they see on a screen, like one object chasing another. This is something that an infant will recognize. An infant will expect one object that chases another to take the most direct route toward the other, not to follow the other's path, but actually to try to catch up. This is an infant less than 1 year old. Clearly we're equipped, and that is something that we have inherited, we're equipped for the perception of causality.
It neglects ambiguity and suppresses doubt and, as mentioned, exaggerates coherence. I've mentioned associative coherence, and in large part that's where marvels turn into flaws. We see a world that is vastly more coherent than the world actually is. That's because of this coherence-creating mechanism that we have. We have a sense-making organ in our heads, and we tend to see things that are emotionally coherent, and that are associatively coherent, so all these are doings of System 1.
Another property -I’ve given it the name "what you see is all there is"- and it is a mechanism that tends not to not be sensitive to information it does not have. It's very important to have a mechanism like that. That came up in one of the talks yesterday. This is a mechanism that takes whatever information is available, and makes the best possible story out of the information currently available, and tells you very little about information it doesn't have. So what you can get are people jumping to conclusions. I call this a "machine for jumping to conclusions". And the jumping to conclusions is immediate, and very small samples, and furthermore from unreliable information. You can give details and say this information is probably not reliable, and unless it is rejected as a lie, people will draw full inferences from it. What you see is all there is.
Now, that will very often create a flaw. It will create overconfidence. The confidence that people have in their beliefs is not a measure of the quality of evidence, it is not a judgment of the quality of the evidence but it is a judgment of the coherence of the story that the mind has managed to construct. Quite often you can construct very good stories out of very little evidence, when there is little evidence, no conflict, and the story is going to end up good. People tend to have great belief, great faith in stories that are based on very little evidence. It generates what Amos and I call "natural assessments", that is, there are computations that get performed automatically. For example, we get computations of the distance between us and other objects, because that's something that we intend to do, this is something that happens to us in the normal run of perception.
But we don't compute everything. There is a subset of computations that we perform, and other computations we don't.
You see this array of lines.

There is evidence among others, and my wife has collected some evidence, that people register the average length of these lines effortlessly, in one glance, while doing something else. The extraction of information about a prototype is immediate. But if you were asked, what is the sum, what is the total length of these lines? You can't do this. You got the average for free; you didn't get the sum for free. In order to get the sum, you'd have to get an estimate of the number, and an estimate of the average, and multiply the average by the number, and then you'll get something. But you did not get that as a natural assessment. So there is a really important distinction between natural assessment and things that are not naturally assessed. There are questions that are easy for the organism to answer, and other questions that are difficult for the organism to answer, and that makes a lot of difference.
While I'm at it, the difference between average and sums is an important difference because there are variables that have the characteristic that I will call "sum-like." They're extensional. They're sum-like variables. Economic value is a sum-like variable.
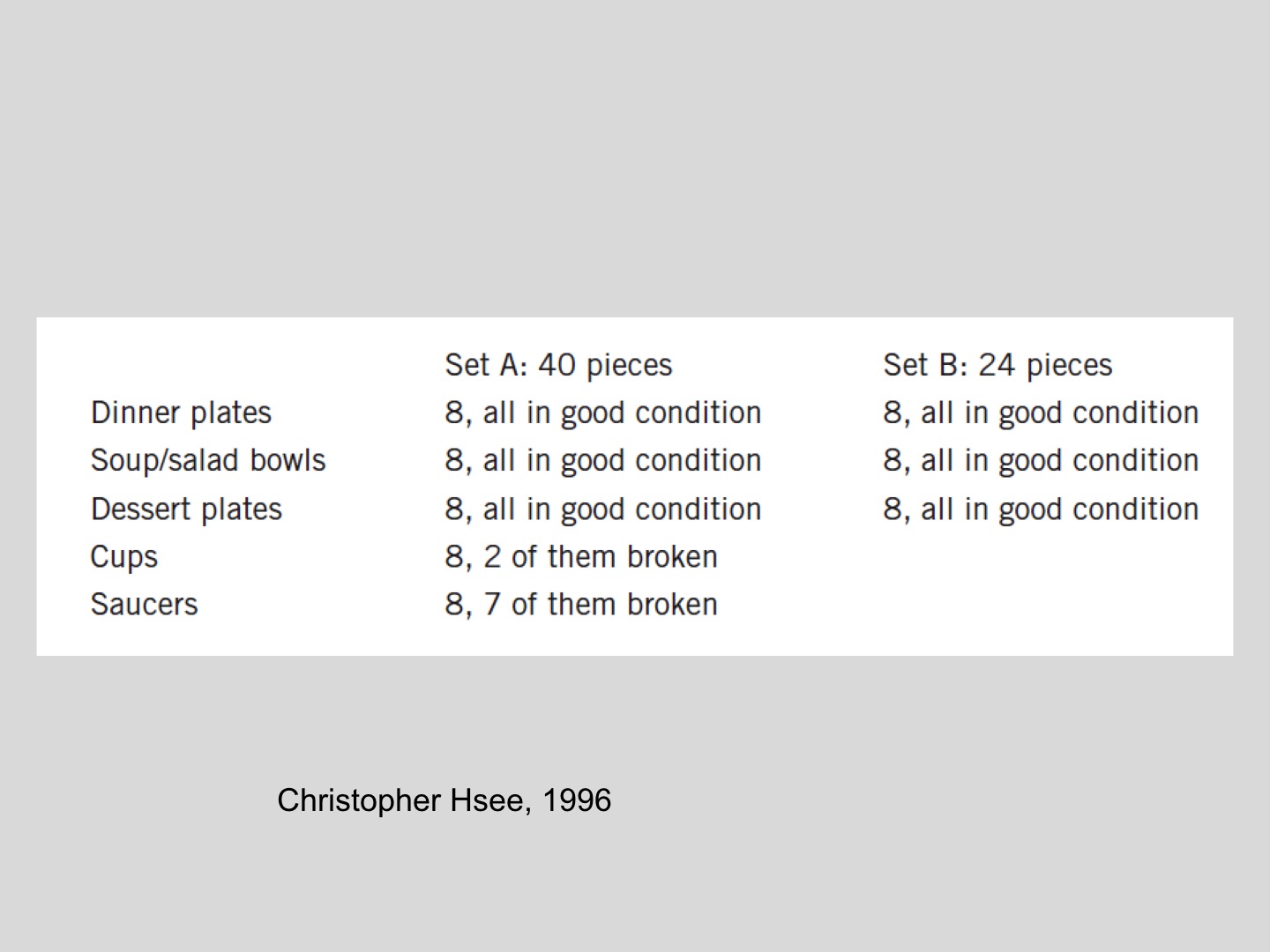
Here is a nice experiment by Christopher Hsee. He asks people to bid for sets of dishes. You have set A, and you have set B. There are two conditions in the experiment. In one condition people see this display. In the other condition, they see set A separately, or set B. Now, when you do it in this condition, the solution is easy. Set A is worth more than set B. It's got more dishes. When you see them separately, set B is valued a lot more, like $10 more than set A, because the average value of the dishes is higher in set B than in set A, and we register the prototype, and we fail to see the other. That happens all over the place.
Among other things, by the way, probability is a sum-like variable. The probability adds up over components, but we judge it as if it were an average-like variable, and a lot of the errors in probability judgment come from that type of confusion.
There are two other characteristics that I want to mention of what System 1 is capable of doing. It is capable of matching intensities. This is fairly mysterious how he does it, but I'll give you an example. Julie, I'd say, read fluently when she was age 4. Now, I could ask you, a building of how many stories is as tall as Judy's reading capacity was at age four? And you can do it. There will be substantial agreement — that is, some people will say, "two stories", that’s just not enough, and 25 stories may be too much". We have an idea. We have an idea of what GPA matches. Interestingly enough, when you ask people to predict Julie's GPA, you say she's graduating from Yale now. They predict the GPA by matching the GPA to their impression of how well she read at age 4, which is a ridiculous way of doing it, but that's what people do.
Matching intensity across dimensions is something that System 1 is capable of doing, and it's extremely useful because, as you will see, it allows people to answer their own question, which is what we do most of the time. It computes more than intended. The mental shotgun is you have an intention to do something, and typically what this generates is multiple performances, not a single activity, but many things at once will happen.

Here is an example. Do these words rhyme? Here people hear the words, and they don't see them. I'm showing them to you, but the participants don't see them. "Vote note, vote goat". Both of them rhyme. People are much slower when they hear the words of a speaker that "vote, goat" rhymes than that "vote, note" rhymes. How do you explain that? Well, they have generated the spelling. They're not supposed to generate the spelling. Nobody asked them to generate the spelling, it's just in the way, they can't help it. They're asked one question, they answer other questions.

Are these sentences literally true? You spend time explaining that this is not metaphor, we don't want you to compute metaphors. "Some roads are snakes" is really slow to be rejected as literally true because it is metaphorically true. People compute the metaphor even when they're not supposed to compute the metaphor. "Some jobs are jails". People are very slow. "Some jobs are snakes" is very easy. There is no metaphor. What you get, the image that I'm trying to draw of how System 1 works, is that it is a mental shotgun, it computes a lot more than it's required to compute. Sometimes one of the things it computes turns out to be so much faster than what it's trying to compute that it will generate the wrong thing.
The main things that Amos Tversky and I worked with are cases in which similarity is used instead of probability. Our most famous example is a lady named "Linda". I don't know how many of you have heard of Linda. Linda studied philosophy in college, and most people think she was at Berkeley. She participated in anti-nuclear marches, she was very active, she's very bright, and ten years have passed, and what is she now? Is she an accountant? No. Is she a bank teller? No. Is she a feminist? Yes. Is she a feminist bank teller? Yes. You can see what happens. She a feminist bank teller because, in terms of similarity, it's perfect to say that she's more like a feminist bank teller than she is like a bank teller. In terms of probability, it doesn't work. But what happens is when you're asked to compute probability, probability is hard, similarity is immediate; it's a natural assessment. It will come in first, and it will preempt the correct calculation.
That was our argument. It has been contested, including even by people in this room, but that's what we proposed, and that was the general idea — a heuristic is answering the wrong question. That is you're asked one question, and instead of answering it, you ask a related question, an associatively related question. There are other views of heuristics. Gerd Gigerenzer, who has a view of heuristics, as formal operations that he calls "fast and frugal" because they use very little information, and they sometimes reach quite accurate estimates. I would contest that because the way I view this, there is no need for frugal operations. The brain is a parallel processor, it can do many things at once, and it can operate on a lot of information at once and there may be no need for it to be frugal.
Now, what can't it do? It cannot deal with multiple possibilities at once. Dealing with multiple possibilities at once is something we do consciously and deliberately. System 1 is bound to the suppression of ambiguity, which means one interpretation. It cannot do sum-like variables. Sum-like variables demand another kind of thinking. It is not going to do probability properly, it is not going to do economic value properly, and there are other things that it will not do.
Here an important point is how you combine information about individual cases with information with statistical information. I'm going to argue that System 1 has a lot of trouble with statistics. System 1, and here I believe the analogy from perception is very direct, it's intended, or designed, to deal with individual particular cases, not with ensembles, and it does beautifully when it deals with an individual case. For example, it can accumulate an enormous amount of information about that case. This is what I'm trying to exploit in calling it System 1. It's coming alive as I'm describing it. You're accumulating information about it. But combining information of various kinds, information about the case, and information about the statistics, seems to be a lot harder.
Here is an old example.
There are two cab companies in the city. In one, 85 percent of the cabs are blue, and 15 percent of the cabs are green. There was a hit-and-run accident at night, which involved a cab. There was a witness, and the witness says the cab was green, which was the minority. The court tested the witness -we can embellish that a little bit - the court tested the witness and the finding is the witness is 80 percent reliable when the witness says "blue", and when the witness says "green", it's 80 percent reliable. You can make it more precise, there are complexities, but you get the idea. You ask people, what's your judgment? you've had both of these items of information, and people say 80 percent, by and large. That is, they ignore the base rate, and they use the causal information about the case. And it’s causal because there is a causal link between the accident and the witness.
Now have a look at a very small variation that changes everything. There are two companies in the city; they're equally large. Eighty-five percent of cab accidents involve blue cabs. Now this is not ignored. Not at all ignored. It's combined almost accurately with a base rate. You have the witness who says the opposite. What's the difference between those two cases? The difference is that when you read this one, you immediately reach the conclusion that the drivers of the blue cabs are insane, they're reckless drivers. That is true for every driver. It's a stereotype that you have formed instantly, but it's a stereotype about individuals, it is no longer a statement about the ensemble. It is a statement about individual blue drivers. We operate on that completely differently from the way that we operate on merely statistical information that that cab is drawn from that ensemble. So that's a difficulty that System 1 has, but it's also an ability that System 1 has. There is more along those lines, of course, it's been a long study.
But I want to talk a bit about marvels and flaws. So far, true to myself, I've spoken mostly of flaws. There is expertise, and expertise is in System 1. That is, expert behavior is in System 1. Most of the time we are expert in most of what we do. Sometimes it's very striking. I like the example that I pick up the phone, and my wife, Anne, says one word and I know her mood. That's very little information, but it's enough. That is expertise of a high order. How did it come about? It came about through reinforced practice, a lot of reinforcement, and a lot of practice. All of us are experts on things. The stories about fireground commanders, or about physicians who have those marvelous intuitions, they're not surprising if they have had the opportunity to learn as much about their field as I have learned about Anne on the telephone, then they're skilled. It's in System 1; it comes with complete confidence.
What's interesting is that many a time people have intuitions that they're equally confident about except they're wrong. That happens through the mechanism that I call "The mechanism of substitution". You've been asked a question, and instead you answer another question, but that answer comes by itself with complete confidence, and you're not aware that you're doing something that you're not an expert on because you have one answer. Subjectively, whether it's right or wrong, it feels exactly the same. Whether it's based on a lot of information, or a little information, this is something that you may step back and have a look at. But the subjective sense of confidence can be the same for intuition that arrives from expertise, and for intuitions that arise from heuristics, that arrives from substitution, and asking a different question.
Clearly the marvels are more important than the flaws. That is in the quantitative sense, in the sense that most of what we do is just fine, and that we are well adapted to our environment, otherwise we wouldn't be here, and so on. The flaws are of some interest, and the difficulty of separating intuitions that are good from intuitions that are not good is of considerable interest, including applied interest. But that's roughly, where we are.
|
|
|


I went back, because we were having that conversation almost 20 years ago, a conversation or a debate with Leda Cosmides and John Tooby, about some of our problems, and I'll mention that problem here. This is a study that Amos Tversky and I did about 30 years ago. A health survey was conducted in a sample of adult males in British Columbia of all ages and occupations. "Please give your best estimate of the following values: What percentage of the men surveyed have had one or more heart attacks? The average is 18 percent. What percentage of men surveyed both are over 55 years old, and have had one or more heart attacks? And the average is 30 percent." A large majority says that the second is more probable than the first.
Here is an alternative version of that which we proposed, a health survey, same story. It was conducted in a sample of 100 adult males, so you have a number. "How many of the 100 participants have had one or more heart attacks, and how many of the 100 participants both are over 55 years old and have had one or more heart attacks?" This is radically easier. From a large majority of people making mistakes, you get to a minority of people making mistakes. Percentages are terrible; the number of people out of 100 is easy.
There are some interesting conversations going on about ways to explain this, and Leda and John came up with an evolutionary explanation which they may want to discuss. I came up with a cognitive interpretation that is, for me, what happens. We don't have the goods on that, actually, but I'm pretty sure we're right. For me, what happens when I have 100 participants rather than percentages is I have a spatial representation. If I have a spatial representation, and all the 100 participants, or the people with one or more heart attacks are in one corner of the room, and then the people who from that set who are also over 55 years old, well, there are fewer of them in that corner of the room. For me, there is a purely cognitive interpretation of the frequency advantage, which is because speaking of individuals, of a number of individuals, calls for a different representation, as far as I'm concerned, in System 1, which will enable you to work with this differently.
Yesterday at lunch, Steve Pinker and I were having a conversation that is quite interesting, about which of these modes of explanation is the more powerful. And it may turn out that it's not even a question of more powerful. Why do I like one, and why do the three of you guys like another? I thought that this might be something on which we might want to spend a few minutes because it's a big theme, the evolutionary topic has been a big theme here. And it's not that I don't believe in evolution. It must be very clear from what I've said that this is anchored. But it is not anchored in the idea that evolution has created optimal solutions to these problems, that it is not anchored in. I thought that we might want to answer any questions, or else we might just want to discuss this problem.
I'm done.
Q & A
JOHN BROCKMAN: I'd like to hear that discussion.
LEDA COSMIDES: I don't actually see those as incompatible explanations. I think it’s exactly correct that when you represent these as individual countable entities it engages different mechanisms. One of my former students has done some work trying to pull this apart. Some people have claimed that when you have these icons, for example, icons help even little children, but when you have the icons, some people claim it just makes you see the relations of the sets and he has some evidence that there still may be something to that but there is still additional help from the icons, per se, beyond just understanding the sets.
For us, it's more that looking at it, asking this other question, in what form would you have experienced it. For example, birds forage for food. All animals forage for food, they have to solve problems of judgment and uncertainty. That the format in which information would have been presented to you, ancestrally, would have been in these natural frequencies. So if you were going to have mechanisms that could take care of these problems, you might expect them to operate on those formats.
Then there was this other argument that was very interesting to me; the idea is that as you go around the world (it has to do with absolute numbers, natural sampling) so I'm going through a forest and it has cherry trees and apples trees in it, and as I'm going through the forest I'm encountering both. Some have ripe fruit, and some don't have ripe fruit, and if I want to know, given that I see red fruit, how likely is that it that of trees with ripe fruit, or let me put the frequency away; of the trees with red fruit, how many are cherry trees?
Then a little tabulator in my mind is just picking up the number of red fruit, and the hits and false alarms, red fruit and cherry tree, and red fruit and apple tree. Then the base rate is implicit in those numbers because they're implicit in how I encounter them. It's implicit in the encounter rate in that forest. It's sort of interesting because that gives a reason for thinking, well, why should absolute frequencies be so much easier than other ones? So I don't see them as competing explanations, I see them as kind of complementary.
DANIEL KAHNEMAN: This, to me, has been quite interesting because at some stage it was presented as a controversy. We now see, you as well as I, that there is no controversy.
LEDA COSMIDES: Right. The controversy was more about what you were talking about initially, to what extent is something badly designed versus well designed.
JOHN TOOBY: And what is the method for discovering the cognitive design?
DANIEL KAHNEMAN: That is what I find most interesting, because we seem to have different ways of discovering phenomenon, or looking for phenomenon. So you have a theory, and you have an image which is much clearer than mine of what the ancestral environment was in, and it gives you ideas about where the ancestral environment would make easy for people, or hard for humans. And I get my ideas from somewhere else. But fundamentally, is there any difference between the kind of cognitive psychology that we're doing?
JOHN TOOBY: I think there is a difference, in the following sense. First of all, I agree with my wife, that it was a brilliant approach of yours to concentrate on errors, because as you say, it's the best way of discovering the actual algorithms the mind uses. On the other hand, there are an infinite number of cognitive problems you could bombard subjects with, like what's the best life insurance package? All sorts of things that blindly activate different random subsets of mechanisms. If you look for patterns in errors elicited using this method, then researchers are going to be making very important theoretical mistakes, they're going to be making mistakes left, right, and center. That kind of characterization of competencies will be necessarily defined in terms of errors, that is, abstract deviations from some normative theory, which is drawn from statistics, or logic, or something like that. By this method, any deviation is by definition seen as an error, a bias, a fallacy.
On the other hand, what if you change the question to, "What would you expect of an evolutionary history in which not all problems of all formats are encountered with equal frequency, but some things are encountered all of time, and other things are encountered very rarely or not at all?" What if you asked the question, "What's a natural function of the brain?" What's an arbitrary transient use?" Mechanisms will be designed to solve commonly encountered problems, adaptive problems, and performance that diverges from statistical inference or logic may be a feature, not an error.
DANIEL KAHNEMAN: I don't want to get into the details of the cheater detection problem, which is complicated. There are striking similarities in the way that, say, I would look at where we would expect good performance. I've had this work with Gary Klein, who recently was on Edge who is a great promoter of intuition. We worked for a number of years to write a joint paper on when does intuition work and when doesn't it work? Something I cited earlier, is that looking at subjective confidence will not do it because you get high subjective confidence with intuitive answers, right or wrong. We are also looking at the environment for an answer, but we're looking in the current environment.
Our question is what opportunities were available for the individual to learn a skill? If there were opportunities to learn a skill, then presumably the skill has been learned, If they were adequate opportunities with immediate feedback, the skill has been learned, and it will work. We're not looking at the ancestral environment; we're looking in the current environment. We, for example, claim that somebody who thinks that he can make long-term political predictions is deluded because the environment doesn't support long-term political prediction that would be valid, or that Wall Street, the data on the stock market do not support adequate or precise predictions. We would also look at the environment; we're just looking at the current environment....
LEDA COSMIDES: Nothing in what we're suggesting says that there shouldn't be ontogenically calibration to your current environment. There should be mechanisms that calibrate to your current environment. But I would think that it would be very hard even with a lot of expertise. I don't challenge the Linda thing. Everybody gets the same results with the Linda thing, put in that way. And I don't even dispute the explanation that you give for it. It's just that the thing that was interesting to me is that when you put it in the other format you get this very different answer. For example, if I wanted to make somebody more expert in reasoning about probability, I would want to give them information in a frequency format because I think that no matter how much you train them with the single event …
DANIEL KAHNEMAN: Well, so would I.
LEDA COSMIDES: …with the single event of probabilities, they can have all kinds of expertise, but lots of times they're getting the expertise because they figured out to transform it into frequencies and think about it that way.
DANIEL KAHNEMAN: There is no disagreement. What we're talking about is where do our ideas come from. Because I don't think there is a significant disagreement. I never did believe that there was a deep disagreement. You are inspired by a certain way of doing things, and it leads you into certain kind of hypotheses. I am playing a different game, on the same terrain, and I get my hypotheses from something else. I don't see the controversy, is really my point.
LEDA COSMIDES: I have a question for you ... feel free to not answer it.
DANIEL KAHNEMAN: I probably will answer it.
LEDA COSMIDES: We were at Stanford (I used to go to Amos's lab groups) and I get a different sense when I listen to you and when I listened to Amos about your emphasis. Of course, you wrote together, so when you're a student reading these papers, it's a joint product and both minds are contributing to that joint product. When I listen to you, I get a sense of an interest in the psychological mechanisms. When I would be in Amos' lab group, he would say there is no more of a theory than that you could possibly predict such and such.
JOHN TOOBY: He would also say, "I'm not interested in mechanisms. All we've ever proposed is empirical generalizations."
LEDA COSMIDES: He said that, and I said, "But what's the availability heuristic? That sounds like a mechanism to me." I said, "Does your collaborator agree with you, because I think your collaborator has proposed mechanisms?"
DANIEL KAHNEMAN: You're asking would Amos agree with me? He's been dead 15 years.
LEDA COSMIDES: A very big theme for him was that if it wasn't a normative theory, if it wasn't that the only real normative theories would be logic, and subjective expected utility theory. Whereas if you're coming from an evolutionary biology perspective, risk-sensitive foraging theories is a normative theory, but it's about fitness maximization, it's not about these other things and so from our point of view there are other normative theories and the world of normative theories goes beyond just those, and so, yes, I'm curious about, the interplay.
DANIEL KAHNEMAN: Well, obviously, we were quite different people, and so we differed even when we worked together. I was more interested in mechanism, and less interested in normative rules than he was. And, he's been dead 15 years. Mostly the things that are important to me in this have been happening in the last 15 years. We have the new understanding of associative memory, which to me changes the whole picture about what cognition is. And that we didn't have. Amos and I never had a coherent view of two systems. We felt vaguely that there were two systems, and in the sense that there are certain experiments that you run when you believe in two systems, that you don't if you don't draw those distinctions. For us it was a very sharp distinction between asking people direct comparisons, or asking them, as in this Hsee's problem, when you show the two sets, then it's clear that logic applies, when you show them one at a time, then your gut tells you that set B, which is the smaller set, is worth more. We have that, but we were not clear. This has become clearer in the last 15 years.
LEDA COSMIDES: Can I ask you a second question about this System 1 and System 2, and the role of language? Of course, with numbers, there has now been various work on number cognition and there's this interesting mapping that happens, not in all cultures, but in some cultures, between words for numbers and this intuitive number system, which when we give these kinds of problems, and when you give these kinds of problems to people, we're assuming that they've done this mapping. Or in a cheater detection problem, when I give somebody a problem, they need to read the problem, they need to read and understand the scenario in order for the rule to be interpreted as a social contract, and then this very fast judgment about information search parallel, which cards represent potential cheaters, to kick in. I was wondering if you'd talk a little bit about how you think about the relationship between what you think of System 2 and System 1 and language.
DANIEL KAHNEMAN: Mostly I think that it's a strained relationship between the two systems. Now I’m reifying them, and describing them as interacting. Of course, System 1 makes many suggestions. It comes up first with suggestions, with intentions, with impressions, and System 2 mostly endorses them. It's an endorsement. There is some monitoring going on, and most of the time it's like an editor who has a quick look at the copy that's coming in from the journalist, and sends it to the printer. That is a large part of what goes on.
LEDA COSMIDES: But there's at the front end, too, because when you speak, I have to be better representing the words you're saying, and interpreting them before it can activate even this intuitive system. And so there's this interesting interface that's happening through language.
DANIEL KAHNEMAN: I believe that System 1 understands language. Language is not System 2; language is System 1. Otherwise it wouldn't work.
LEDA COSMIDES: Okay. Because a lot of times lately there has been some, especially in social psychology, the strange thing where they think that something is not an automatic system, if in during the interpretive process, when somebody has to interpret the situation, if they put some kind of cognitive load. So you’re not even knowing what the scenario your reading is about because you're thinking about counting backwards by threes or something like this, and that you can't magically do a problem under those circumstances they think speaks against that it's something from System 1. Whereas you can do the same thing where you have the person read the scenario, and then you give them a cognitive load, and it has no affect on their performance as well. So there are a lot of funny things going on in the literature about that.
DANIEL KAHNEMAN: There are interesting differences. I'll give you an example. One thing, in my reading at least, that System 1 can do, is it generates an attitude. There are things, you like them more, you like them less, that's System 1, the immediate emotional response to something. Choice, which is an explicit comparison, always involves System 2, and is always effortful. There is a very sharp boundary in here about certain things that are guaranteed to call, System 2 is going to get called, like in 24 types of tea, and choice is one of them.
JARON LANIER: I just had another thought for a minute, from a computer science perspective. If you compare the task of averaging versus summation, the difference is that summation involves accumulators, there's this variable. And when we do machine learning, it tends to fall into two systems, its slightly analogous to this. I don't know how much. What is it in your system where there's running averages you don't create new variables, or what you would call models, and so you're just tracking some sort of traditional data set.
Then there are others where there is a stored model that you're comparing against, and to have the stored model you need to have a different architecture. I've often wondered if things we’re conscious of correspond to the creation of new stored structures, because the thing is when you create a stored variable, when you’re going to create a model, the number of potential mistakes expands enormously. But if you have a model where you have the same statement, you're just optimizing the energy landscape; you can kind of in a Bayesian way even find your way into a local and even global optimized point. But if you're adding new states, you have this truly gigantic explosion of possible errors, and so it's much more energy-intensive, and much harder to test. I would note that you’re conscious of learning a new vocabulary but not necessarily of using it.
DANIEL KAHNEMAN: The distinction between sum-like and other variables is fascinating. Clearly, there is a big gap between them, and what I call System 1 is clearly able to do one. It deals with individual cases. That's what happened in the example of the cabs, when you get the stereotypes, you have one cab. You don't have to do things, to combine statistical information with single case information. It all goes into the single case, and then it works fine.
JARON LANIER: There's an example in machine vision where you can start with a given, start with a prototype of a facial map and you look and you scan an environment for facial elements that match a face. You track faces, but you don't add it to your model space. If you, instead, define a task where I am going to show you arbitrary new pieces of information, and I want it to have emergent new categories, wow, that is an entirely different class of problem, and that's vastly more difficult, and essentially not understood. My intuition is that this is something like this System 1 System 2 extension.
STEVEN PINKER: I also think there is a little controversy here. I would say, without hesitation, if somebody were to ask me what are the most important contributions to human life from psychology, I would identify this work as maybe number one, and certainly in the top two or three. In fact, I would identify the work on reasoning as one of the most important things that we've learned about anywhere. I argued at Harvard that when we were trying to identify what should any educated person should know in the entire expanse of knowledge, I argued unsuccessfully that the work on human cognition and probabilistic reason should be up there as one of the first things any educated person should know. I am unqualified in my respect for how important this work is. So whatever difference in emphasis is not on whether these are important profound discoveries, which they are, but where to take them, and how ultimately to explain them.
One of the things that you said when introducing your talk that I found very informative, is when you said that the errors are what give us crucial information about how the human mind works. While I know with incorrect performance, there’s a sense in which that's certainly true, there’s also a sense in which correct performance is fantastically informative, in the sense that there are very few systems in the world that can do what a human can do. Our computers can't drive our cars for us, they can't make a bed, they can't put away the dishes, and they can't understand English sentences. So the question of how we do things well is informative in the sense that it's not so easy to get something to do well what humans do well.
The approach of trying to account for the successes strikes me as a convergent way of getting in the mind, as well as the failures. The same way if someone were to ask how does an automobile engine work, how does the eye work, to characterize all of the errors and the flaws is an important source of information, and ultimately it will take you to the description of a spark plug, a carburetor, not necessarily in physiological terms, but even in computational terms, from which the errors would be ultimately deducible as a by-product of what it does well, given that it's so hard to get something to do well what you might have thought.
DANIEL KAHNEMAN: It's difficult, but the idea about errors is that they're much more diagnostic about the mechanisms, so there might be different mechanisms for doing the same thing perfectly, and you're not going to be able to distinguish the mechanism by observing it. Where there is some convergence, Gary Klein and I, our conclusion was if you want to distinguish good intuitions from bad intuitions, don't look inside, don't look at the person, look at the environment. Will the environment support good intuitions? That's essential.
What happened, in part, was that we were identified with flaws. People thought we liked flaws. It’s interesting in terms of the context of the debates, the debate about Linda, and there's been a lot of debate. There are two kinds of arguments, two kinds of debates. In one kind of debate you go after the strongest argument that the other person has made. In other kinds of debates, and it's legitimate, you go after the weakest argument that the other person has made. That is what you do when you want to discredit something.
The argument about Linda has been the discrediting kind of argument, that is, it has taken the most extreme case, which we did not believe would be robust, and it showed that it's not robust. It's perfectly legitimate in an ideological way because we were seen as claiming that people make many mistakes. It's an ideological claim. Now you can find that here is a problem where you can show that people are not making such terrible mistakes; it's a discrediting argument. There has been a lot of ideology around this, and a lot of noise, and a lot of smoke. I had that conversation with Ralph Hertwig and he said "you have no right to complain". So I'm not complaining.
 Ralph Kerle
Ralph Kerle
Reader Comments